 By Ian Milligan
By Ian Milligan
This post originally appeared on ianmilligan.ca.
OK, you’re all forgiven: when you hear ‘open data,’ the first thing that springs to mind probably isn’t a historian (to some historians, it’s the first episode of the BBC show ‘Yes, Minister’). In general, you’d be right: most open data releases tend to do with scientific, technical, statistical, or other applications (releasing bus route information, for example, or the location of geese at the UW campus). Increasingly, however, we’re beginning to see a trickle of historical open data.
Open government is, in a nutshell, the idea that the people of a country should be able to access, read, and even manipulate the data that a country generates. It is not new to Canada: Statistics Canada has been running the Data Liberation Program since at least late 1996, and there have been predecessors before that, but the current government has been pushing an action plan which has materialized in data.gc.ca.
While I am not a fan of the current government’s approach to knowledge more generally, I am happy with the encouraging moves in this realm. Criticism of the government is often very deserved, but we should celebrate good moves when they do happen, however slowly this may occur. Indeed, if the government is opening up their data, maybe it should inspire more publicly-funded scholars to do the same (hat tip to the Canadians and Their Pasts project – profiled here recently – who let me know via Twitter that they are committed to releasing their data).
In this post, I want to show some of the potential that is there for learning about the past through Canadian open data, in the hopes that this will spur interest in maybe getting more released. I even have a little bit for everybody: There’s data here from which political, military and social historians can draw. Let me show you how.
Political Open Data
Political historians can immediately benefit from this data: History of the Federal Electoral Ridings, 1867-2010, particularly the data in the CSV spreadsheet that you can download. It’s a big file, containing the information of 38,778 candidates for federal office in Canada. Without computational methods, or a lot of time, this is quite a bit of data to hand code or figure out – and in any case, now that it’s digitized, we can learn things quite quickly!
It’s a thirteen column file, with the following entries: Election Date, Election Type, Parliament, Province, Riding, Last Name, First Name, Gender, Occupation, Party, Votes, Votes (%), Elected. While some of the data on defeated candidates is sketchy up until the 1920s, and it suffers from not having fully normalized data (as I’ll show you in a second), this is still a treasure trove of information.
The ‘occupation’ tab is worth highlighting, as it shows the advantages and disadvantages of this sort of data in one fell swoop. If we start tallying the occupations, we get the following:
lawyer, 3730
farmer, 2587
teacher, 1415
merchant, 1194
businessman, 1125
physician, 999
barrister 981
parliamentarian 816
student 795
journalist 497
It’s useful because we get a sense of who ran for parliament. It’s troublesome, because we see that people have put in entries that might be better clustered: i.e. “merchant” and “businessman” might belong in the same category, as might “lawyer” and “barrister.” We’re relying on the data as it was submitted, so it’s not going to be perfect.
But still, we can learn quite a bit – shifting occupations of elected and defeated candidates, how party candidates may have changed over time, what occupations are overrepresented amongst the overall, the defeated, and the victorious – and I believe there’s a fantastic MA paper in this data. So here’s a question: How common are lawyers within the candidate pool? More so, do they have a disproportionate level of success at being elected? We know that they were common back in 1867, and anecdotally, they seem to be today.
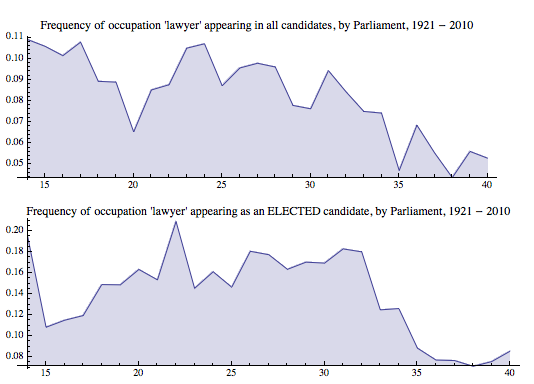
The x axis is referring to the sitting of parliament – so we begin in the 14th parliament and we finish in the 40th.
From this, we see that in the 14th Parliament nearly 11% of all candidates for seats listed their occupation as lawyer (there were some solicitors too, but lawyer was overwhelmingly the way they recorded their occupation). Yet if we drop all the defeated candidates, we see that almost 20% of the successful candidates that year were lawyers. So there were a lot of lawyers up for election, and they were disproportionately successful at getting elected. Things have dramatically declined since – although, keep an eye on the y axis, we’re not going too low. Still ~9% of our elected candidates in the 40th Parliament listed lawyer as occupation.
Again – we’re relying on the data from this chart – many more lawyers would have listed their occupation as businessman, perhaps, or simply parliamentarian.
But the occupational data is still fun. Let’s take every Liberal Party candidate’s occupation from 1962 onwards and compare this list to the occupations of the New Democratic Party. It speaks volumes about the two parties:
TOP 50 OCCUPATIONS FOR LIBERAL PARTY CANDIDATES FROM 1962 ONWARDS
{lawyer,737},{parliamentarian,412},{businessman,251},{farmer,212},{Member of Parliament,142},{teacher,138},{administrator,82},{consultant,71},{politician,68},{physician,56},{barrister,56},{merchant,54},{manager,53},{economist,52}
TOP 50 OCCUPATIONS FOR NEW DEMOCRATIC PARTY CANDIDATES FROM 1962 ONWARDS
{teacher,484},{student,192},{lawyer,179},{farmer,150},{professor,71},{retired,70},{union representative,69},{social worker,52},{parliamentarian,51},{Member of Parliament,48},{journalist,43},{businessman,43},{administrator,38},{consultant,37},{university professor,37}
Again, this is just from putzing around with open data. There’s potential!
Military Open Data
There is only one formal dataset in the Open Data collection: the metadata that runs Library and Archives Canada’s attestation paper database – the Soldiers of the First World War database. It’s a big file: over 600,000 names and service numbers. Secondly, we can also draw on the data from the Commonwealth War Graves Commission’s (CWGC) website database of the war dead, which lets you download data in CSV format. We can actually compare these two data sets and see who lived and who died.
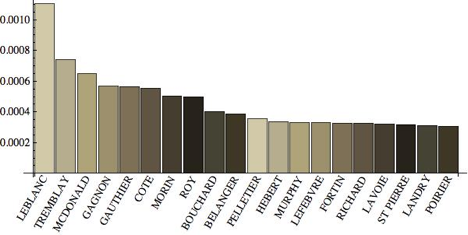
If we combine the information from the Library and Archives Canada attestation papers database and the information from the CWGC. By doing so, we can get a sense of the names that are overrepresented in the graves, as well as those underrepresented. What can we find? First, we can generate a list of the top twenty overrepresented names and the degree to which they were so:

Names that were over-represented in the War Graves data versus the attestation data
In the graph above, we see that Smiths in the CEF were approximately one percent more likely to die than the “average” CEF soldier; 1.1% of all soldiers in the CEF had the surname Smith, and 1.2% of the casualties did as well. These are at a glance English/Irish/Scottish names, a distinction that becomes clear when we generate a similar list of those soldiers who were less likely to die than average.
Under-represented names.
French names were less likely to be found amongst the death rolls of the First World War, as well as the single English outlier McDonald (representing 0.45% of CEF soldiers, but only 0.39% of deaths). After some digging, my sense is that we’re seeing the overrepresentation of Anglophones, recent English immigrants to Canada, who joined the CEF in the initial wave of optimism in 1915 and 1916, declining thereafter.
Social History: Birth, Death, and Marriage
This is going to be a bit less developed, as one of the major CSV files is currently not working (I have a ticket in with the Open Data Ontario people). But check out what we have on births:
Birth registrations in Ontario (by location), 1912-2010
Ontario top baby names (male), 1917-2010
Ontario top baby names (female), 1917-2010
And then we also have the:
Marriage registrations in Ontario (by location), 1927-2010
With this data, it is likely we will be able to see connections between marriages and births in various communities (any place with over five babies being born is included), and start mapping out some of Ontario’s demographic history. Again, this has been possible and has been done many times before, but it is now much easier.
All news on this front is not rosy. Many social historians drew on the old E-STAT database, which allowed people to draw on extensive amounts of historical census data. Yet now, if we go to this site we see that many of the links do not work – they are being migrated to the new CANSIM portal. Much of this does not appear to be up yet, and from colleagues I gather that the migration was not handled perfectly. If moved over, however, it would be an incredible resource!
Conclusions
This is just a quick tour through some possibilities! I think there’s some neat work to be done here, and I’m always happy to chat with people if they ever want to play with historical data. These aren’t my areas of expertise, but playing with data is.
So when you hear something about Open Data, such as a consultation or a call for engagement, if you’re a historian it’s worth speaking up. Let’s get more data!
Ian Milligan is an assistant professor in the Department of History at the University of Waterloo. He strongly believes that the UW Open Data on Geese will save his shoes one day.

This is a good post, Ian, and definitely brought to light certain data sets that I didn’t know existed. Would you consider census data to be part of “open data?” If so, I think it’s important, in light of this initiative and the recent privatization of access by Ancestry.ca, to highlight the usefulness of census data to historians as something that can show trends, but also help with the details. I frequently refer to censuses for basic genealogical inquiries. I’m glad to know that other resources, such as birth registrations, exist, but it’s concerning that the public is losing access to other types of data.
This was an introduction to some data sets that have been recently introduced and that people may not think of. I think you can certainly include the census in the broad category of open data. It brings additional difficulties, of course, which are that it’s very labour intensive to create due to handwriting. It would be nice to have it all downloadable in nice machine-readable format, however, and so the recent moves by ancestry.ca are not conducive to that.